Collaboration Tree
The tree visualizes University of Mississippi Medical Center's educational hierarchy with end node containing the contact person for that department. This tree is developed by University of Mississippi Medical Center's Biostatistician Chad Blackshear and Data Scientist Radhikesh Ranadive.
- Click on the nodes which are filled with color to expand.
- Hide the child nodes by clicking on the parent node.
- Some of the child nodes have contact information of a person, to email them just click on their name.
- Click and hold to drag the tree around.
- Also have zooming in and out functionality.
How it works
Description
- The tree is variation of the original collapsible tree.
- Some of the modifications from the original visualization are making it vertical, adding separation between nodes and adding zooming in functionality.
- The data input has to be n+1 column CSV file, where n is the number of hierarchical levels in the tree.
- Schema of the CSV :
parent (int/string): The parent name of the hierarchical tree, this will be the first node in the hierarchy and is at level 0.child_1 (int/string): This node is at level 1 contains school name and is the child of parent node.child_2 (int/string): This node is at level 2 contains department name and is the child of child_1 node.child_3 (int/string): This node is at level 3 and contains child of child_2 node.email_id (string): Email id of the contact person in the respective department.contact_name (string): Contact name of the person in the respective department.
- Following steps are used to convert the CSV file into hierarchical form:
- Loading required libraries and dataset
- Convert the wide data in each row of the CSV file to long format having two columns
level_numandnode_name, not includingcontact_namecolumn from CSV file. - Adding a
parent_namecolumn which will show the parent node at each level. - Create a contingency table with
parent_nameandnode_nameand filtering results having frequency >=1. - To get the contact name that we left in the first step, we need to merge by
node_name(contains email_id) in the filtered results of contingency table withemail_idin CSV file (just includeemail_idandcontact_namecolumns from CSV file). - In merged results, renaming column
contact_nametoemail_idifnode_namecolumn contains email_id then put it in columnemail_idand If columnemail_idcontains contact_name then put it innode_name. - Finally convert the dataframe into json format using d3_json function from d3r library in R.
#loading libraries
library(magrittr)
library(stringr)
library(forcats)
library(plotly)
library(scales)
library(tidyverse)
#loading data
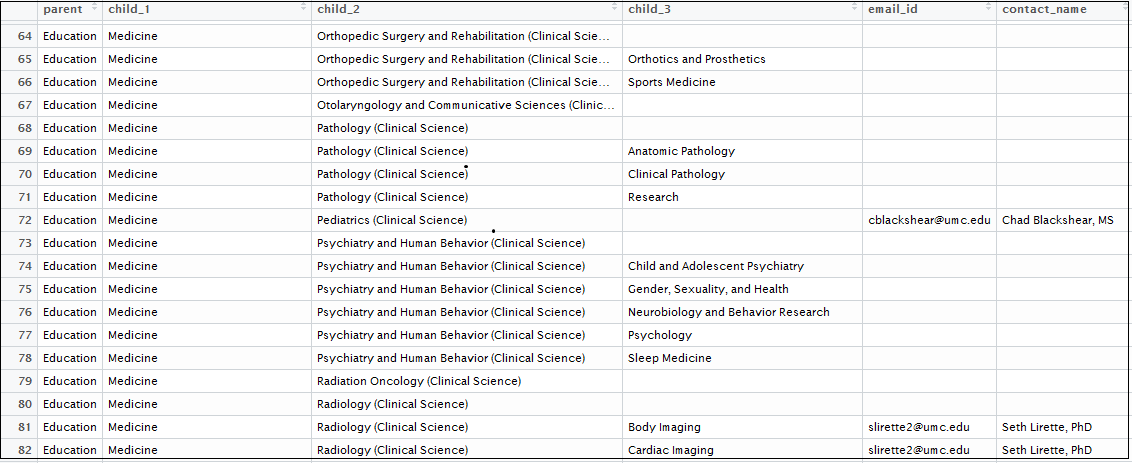
Data <- read.csv('data/tree.csv', stringsAsFactors = FALSE)Below is the Data Frame Structure:
#conveting wide data into long format:
treeH <- data.frame(matrix(data=NA,nrow=nrow(Data)*4,ncol=2))
colnames(treeH) <- c('level_num','node_name')
j=1
for ( i in 1:nrow(Data)) {
t=0
for (k in 1:5) {
if (Data[i,k]!= "") {
treeH$level_num[j] <- t
treeH$node_name[j] <- Data[i,k]
t <- t+1
j <- j+1
}
}
}
# getting complete cases
cc <- (complete.cases(treeH$level_num,treeH$node_name))
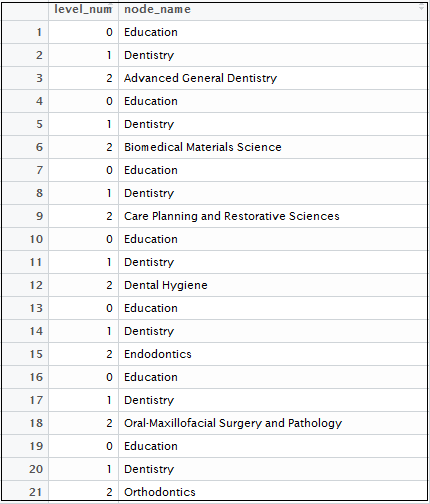
treeH <- treeH[cc,]Data frame converted to wide format:
treenew <- data.frame(matrix(data=NA,nrow=nrow(treeH),ncol=3))
colnames(treenew) <- c('level_num','parent_name','node_name')
for (i in 1:nrow(treeH)){
if(treeH$level_num[i] == 0){
treenew$parent_name[i] <- 'No parent_name'
treenew$node_name[i] <- treeH$node_name[i]
treenew$level_num[i] <- treeH$level_num[i]
}
else {
treenew$parent_name[i] <- treeH$node_name[i-1]
treenew$node_name[i] <- treeH$node_name[i]
treenew$level_num[i] <- treeH$level_num[i]
}
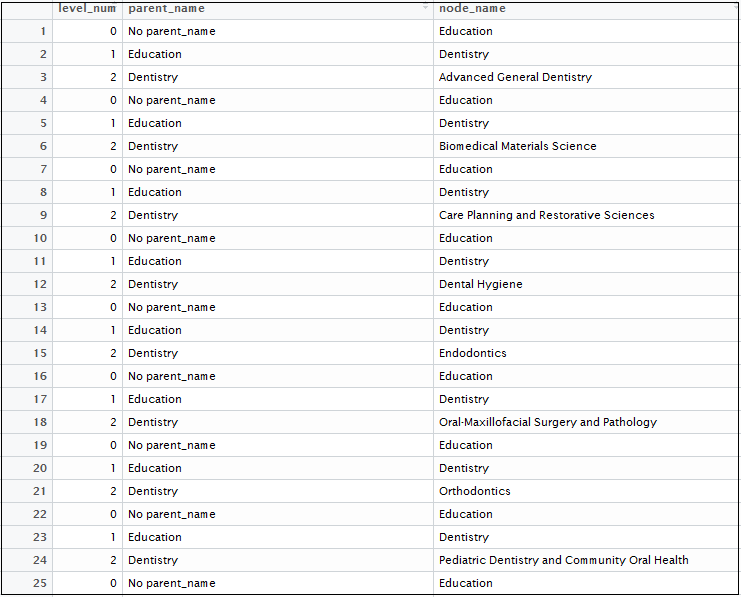
}Added parent node name:
treeFinalnew <- data.frame(table(treenew$parent_name,treenew$node_name))
treeFinalnew <- subset(treeFinalnew, treeFinalnew$Freq >= 1)
colnames(treeFinalnew) <- c('parent_name','node_name','value')
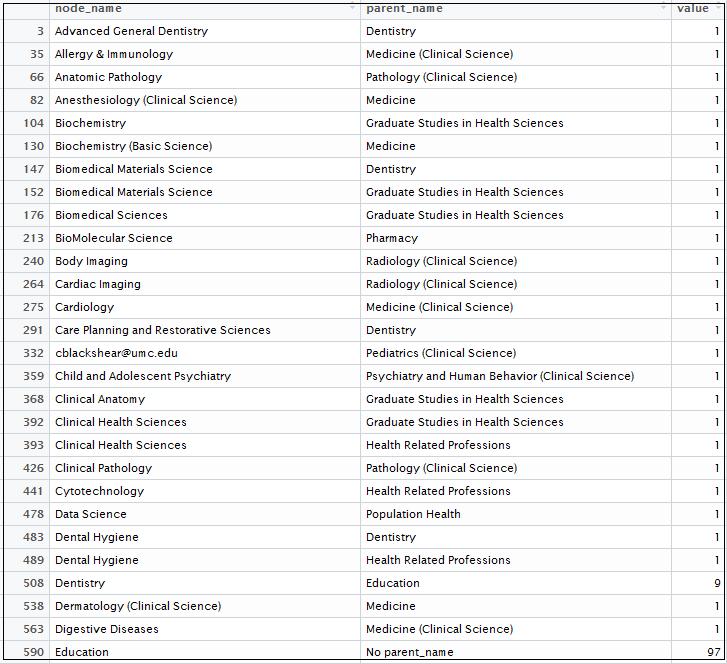
treeFinalnew <- treeFinalnew[,c(2,1,3)]Below is the contingency table:
DataSubset <- Data[,5:6]
#removing duplicated rows
DataSubset <- unique(DataSubset)
#adding the node_name to dataframe by merging with raw data (just cols email_id and conatact_name) by email_id and node_name
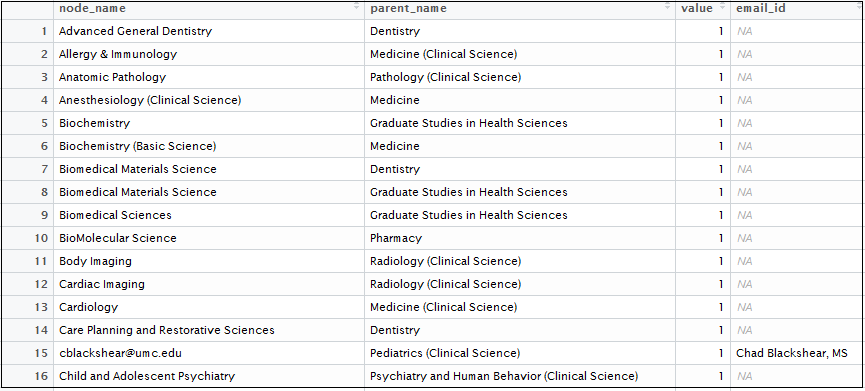
treeFinalnewMerged <- merge(treeFinalnew,DataSubset, by.x = c("node_name"), by.y = c("email_id"), all.x = T)Added Contact name:
# renaming contact_name as email_id
names(treeFinalnewMerged)[4] <- 'email_id'
treeFinalnewMerged$node_name <- as.character(treeFinalnewMerged$node_name)
#replacing the names in node_name with actual contact_name and email in email_id with actual email
for (i in 1:nrow(treeFinalnewMerged)) {
if (!is.na(treeFinalnewMerged$email[i])) {
x <- treeFinalnewMerged$email[i]
y <- treeFinalnewMerged$node_name[i]
treeFinalnewMerged$node_name[i] <- x
treeFinalnewMerged$email_id[i] <- y
}
}Below is the final data frame structure:
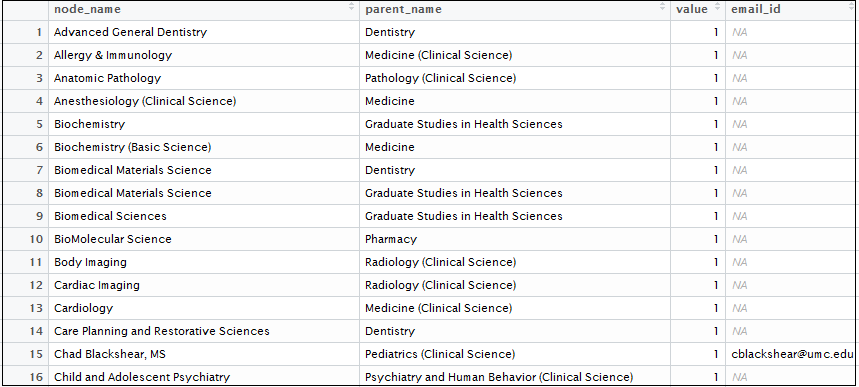
#converting the data into json format
library(d3r)
d3_json(treeFinalnewMerged)